
Life At The Edge
Local access vs. edge intelligence, and the fractals of compute

My thanks to Michael Dempsey and Aliisa Rosenthal for reading drafts of this essay. Disclaimer: In 2021 I invested in Edge Impulse and in 2023 I invested in Ditto, both companies provide infrastructure for edge compute.
1.
Computing advances in fractals of concentration and diffusion. A new technology requires concentrated resources; as it develops, it diffuses. But each evolution does not displace the last. It carries parts of what came before.
Mainframes, centralized behemoths in cavernous rooms, diffuse to personal computers. Networking connects those PCs and enables the web. Over time, infrastructure concentrates into the cloud, accessed through a diffuse and capable network of laptops, smartphones, and tablets. Computation becomes cheaper and spreads wider. A $499 smartphone can render a video that once required a $50,000 workstation.
The mainframe period of AI is ending. Many basic AI functions today are performed in web interfaces or through APIs that serve as terminals to centralized data centers. A lot of that computation will be much cheaper and happen on the user’s device in the future. But that does not portend a wholesale shift. The fractals carry on; cloud and edge AI will blend together.
2.
Is Figma a cloud application? Somewhat. You interact with the application in your browser and files are stored online. But the complicated math to render vector paths and pixels happens on your device because it needs to happen instantly1. Any lag hampers usability significantly. This local computation elegantly resolves with changes in the cloud: cursor positions, collaborator edits, and so on. The end experience feels lightning fast despite allowing seamless collaboration because of this dance of edge and cloud.
The dance isn’t uncommon. Netflix is the poster-child of a new category enabled by high-bandwidth cloud-based streaming, but it relies in part on hardware video decoding happening on the user’s device. Without it, the service can’t use efficient, modern video codecs, which impacts bandwidth requirements, cost to serve, and performance. Google Maps relies on your machine to make zooming and panning feel smooth. Notion renders text on your machine before it’s synced to the server.
Cloud applications can feel like portals we access from dumb terminals, but they are not wholly abstracted from the edge. AI will follow the same pattern. The fractals continue.
3.
Edge compute is not the same thing as local access.
Edge compute is about where the computation happens: on your device, rather than in a data center. A given computation is likely to be more reliably performant at the edge. Latency is lower, making some use cases newly viable2. Connectivity isn’t required for the compute to happen, so bandwidth-constrained environments come into play. It is more private, and in some ways more secure. Systems that selectively use edge compute can be more resilient than a system that relies fully on centralized compute3.
Local access is about what the computation can see and touch. Using a model limited to a chat window in the cloud is like having an autonomous car that’s only allowed to drive you to and from certain places. Not only does it limit utility, it limits your creativity and belief in what the tool can do for you. This is part of why Claude Code spread like wildfire, and was turned into Cowork. Removing those constraints is a step change.
The internet is awash with people buying Mac Minis to run OpenClaw (née Clawdbot) on. But for most of those users, that Mac will just barely test its compute capacity. It is mostly being used to orchestrate actions and provide local access to the user’s file system, data, and applications. That brings into play files and context that AI models cannot easily access through straightforward integrations, like your downloaded files or your messaging apps.
For most users, the actual inference is still happening in a data center, and Anthropic (or their vendor of choice) is still charging for the tokens they burn through4. Files and context are still being uploaded to the compute vendor’s cloud. The benefits of local access are spreading quickly, but the benefits of edge compute have yet to manifest.
4.
In the short term, I expect a lot of innovation that furthers and extends this local access concept. It’s another step in the quest to open up more of our world to AI models.
We started with relatively simple or brittle approaches to do so: file uploads, integrations, virtual machines and browsers like Operator, simple MCP connectors, and so on. Claude Code and Cowork take more direct approaches, providing cloud models direct access to the local file system. We’ll continue to see this paradigm extended: to files, applications (e.g. Claude for Excel), and the operating system itself.
Of course, some of the magic of “local access” today is actually remote local access. The mainframe is (partially) back. It just lives on your desk and you can talk to it in plain English from anywhere. We’re used to accessing everything from everywhere, and that expectation is here to stay:

Local access solves a context problem. Granola, the meeting notes app, installs as a native application, because it needs OS-level access to system audio5. But the transcription and note-taking that is the magic of the product does not happen locally. Audio recordings are sent in real-time to cloud servers where the inference happens.
As users get comfortable with local access, they’re also getting comfortable with the idea that AI can live ever closer to their machines. That comfort will also be a lever that helps edge compute gain a stronger foothold.
5.
So, the ghost in the proverbial machine is becoming more enmeshed with our physical machines. But inference is largely still happening in the cloud. History tells us that compute that is centralized and expensive will become diffuse and cheap. So we can expect much more inference to also happen locally.
Inference requires power, processing, and memory. The vast majority is happening in large data centers, which are being built at breakneck speed. Hyperscalers have been very clear that they are supply constrained; in other words, there is more demand for inference than we are able to serve. There is a huge trade underway to build out this supply. The underlying assumption is that demand is here to stay and will continue to grow.
There is no doubt more inference will happen at the edge. The investor Gavin Baker cites edge inference as one of the few key threats to the data center buildout6. The key questions are the magnitude and duration of this shift.
And there is an investment cycle underway at the edge, too. Apple has led the way: their unified memory architecture is exceptionally well suited to efficient inference, and the latest iPhone and Mac events emphasized progress on neural chips and battery life. Microsoft now labels PCs with processors capable of over 40 TOPS that can run useful models locally, and manufacturers are racing to invest in the associated adoption cycle. Software improvements help too: smaller and more efficient models make yesterday’s frontier viable on cheaper hardware.
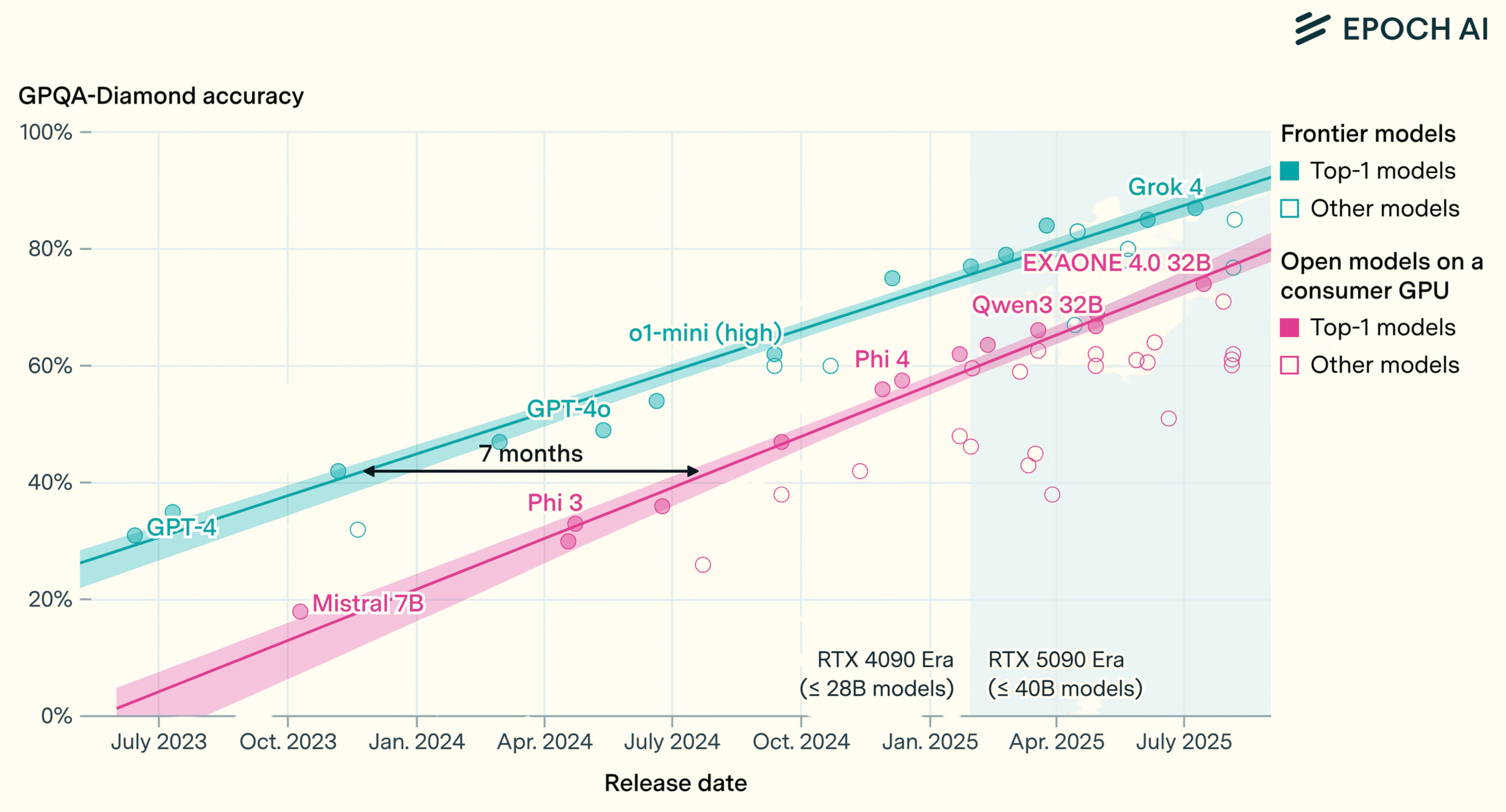
Analysis from research institute Epoch shows that state-of-the-art cloud inference performance can be replicated on top-of-the-line consumer hardware with an average lag of 12 months. More importantly, their research shows the gap between performance of cloud frontier models and on-device consumer models converging. Technological shifts start centralized and power hungry, then diffuse and cheap. The edge is catching up.
6.
More inference happening on your device means it really matters what inference your device can do.
Consumer hardware has been somewhat boring for nearly a decade. An iPhone 17 largely does what an iPhone 12 can. For most people, the gulf between MacBook Air and MacBook Pro has narrowed to immateriality. Some never really use an application other than the web browser, itself a portal to web applications that abstract their compute needs to the cloud.
The physics of on-device inference change this equation. A MacBook with abundant unified memory is much more capable at inference than an iPhone. Increased investment in edge inference means a steep improvement curve, and each new generation of devices will be meaningfully more capable at AI tasks than the last. Gavin Baker’s analysis suggests a current state-of-the-art cloud model could run entirely on a phone (with additional battery and memory headroom) within three years.

Consumer hardware will matter again. A new MacBook launch may be meaningful once more: the polished keynote slide showing a leap in intelligence you can truly utilize, instead of an abstract increase in performance. The diffusion cycle that made compute personal in the 1980s and 1990s will repeat to make intelligence personal.
7.
The likeliest early adopters of edge inference are consumers with extreme needs. Just as ‘pros’ who use their machines for photo & video editing, rendering, and programming have long bought top-of-the-line machines, those who are power users of cloud inference may find the rent-vs-own equation shifts to favor the latter as the edge continues to catch up. Such users are used to understanding the limits of their hardware and upgrading when necessary. “Free” compute at the edge provides room for play and experimentation without constraining usage.
Claude Code power users may shift to locally-run OpenCode instances. WisprFlow users might move to Handy. Or the privacy enthusiast: as models go from utility to companion, local intelligence will feel safer and more intimate than a cloud-hosted oracle.
Independent developers and boutique software makers will also drive the use of edge inference. Apple’s Foundation Model Framework allows iOS and Mac app makers to use models that run fully on-device in lieu of cloud calls. Frameworks like RunAnywhere give developers cross-platform options for private on-device AI. The capabilities of these tools will improve rapidly, allowing developers to build features at no visible cost to themselves or their users.
8.
Things look a little different for the average consumer or knowledge worker. The maturation of the SaaS era resulted in a cloud-based web application equilibrium that was almost wholly agnostic of the user’s hardware. This user expects feature parity regardless of device: there is nothing they cannot do on their phone that they can do on their laptop or tablet. They are mostly served by large venture-backed or public businesses that want data and information to flow through their infrastructure to further increase their platform’s gravity, and therefore prioritize the cloud.
For edge inference to play a more meaningful part here, adoption of hardware capable of efficient inference has to become widespread, and software tooling that makes it easier for application providers to switch between cloud and local inference depending on the situation (accessing something from a phone vs. laptop, for instance) has to mature.
But there are also other incentives in favor of the edge. Products making meaningful use of AI models do not enjoy the luxury of historical SaaS margins. Offloading parts of their inference load to the edge helps shift unit economics favorably. And some use cases are already ripe for that shift. Transcription, voice-to-text, simple analysis, summarization: many workloads are now viable at the edge. There are other benefits, too, such as the security and privacy improvements for a product like Granola moving transcription to the edge7.
9.
History guides us to expect diffusion. But there is an anomaly. Traditional software is deterministic: a spreadsheet on a mainframe gives the same output as a spreadsheet on a PC. With AI, the quality of model materially affects the quality of thinking, of experience, of output. Using Anthropic’s Opus 4.5 model with high reasoning can make an experience feel possible or natural compared to the lower-tier Sonnet model, even though the latter is very capable8.
And God models, the most powerful and capable models, need the most advanced hardware and therefore live in the cloud for the foreseeable future. Even as the gap between open source and cloud closes, hardware requirements for the most capable models will surpass most readily available consumer devices.
For some use cases, this won’t matter. Physical AI, for instance, will largely be an edge endeavor. Robots on a factory floor, autonomous vehicles9, and drones cannot wait for a cloud round-trip. Latency and connectivity constraints will force adoption of capable edge hardware.
Elsewhere, the slope of model development will determine how critical the God models are. Many enterprise applications today already use models that are a generation or two old, because they are good enough at what needs to be done, and often much faster. But for some consumer and creative experiences, using the very best models may be existential.
10.
Local access is one more step toward bringing files and context to powerful AI models. But it’s an interim step. Fundamentally new primitives for integrating AI into our digital world are next. Applications will shift from enclosed destinations to permissioned capability layers that define what AI models can access and do. Operating systems may have ambient agents working across applications and devices, drawing on context that goes wherever it’s needed.
As these primitives emerge, so will infrastructure that lets applications move fluidly between cloud and edge inference depending on the device, the task, and the user’s preferences.
Computing moves in fractals. We’re at the peak of a concentration cycle. The diffusion has begun.

This happens via WebGL, which renders 2D or 3D graphics within any compatible web browser and can take advantage of the GPU on the user’s device to do so.
Slight latency takes experiences from magical to frustrating. Rabbit and Humane struggled in part due to the lag of faraway inference.
This isn’t just limited to inference. Chick-fil-A uses Ditto (disclaimer: I am an investor) to turn point-of-sale systems cloud-optional, so restaurant operations are unaffected if internet connectivity is temporarily interrupted.
More intrepid users are indeed running local models on their Mac Minis. But the capabilities of what that software/hardware combination can do today are very limited compared to powerful cloud models. An even smaller subset of users do, however, have very powerful local model setups often involving multiple devices networked together (using tools like Exo) to provide the increased memory required for more capable local models.
After years of web apps becoming dominant, native applications (that install on the operating system instead of running within the web browser) are once again gaining favor due to precisely this kind of benefit.
Meanwhile, Will Manidis makes an argument for the structural existentialism of the trade:

From Granola’s security documentation: “In order to provide the best transcription and AI summarization quality, we do these in the cloud. We initially tried doing them locally on device, but the computation was too much and it slowed down your computer so now we do transcription and inference in the cloud.” That computation limitation is rapidly going away.
In general, most people vastly underrate the gulf between the model most providers default to vs. the most capable reasoning offerings. And some models are ineffably better at some things than other ‘equivalent’ models.
In addition to 29 cameras, Lidar, and radar, Waymo’s Jaguars carry a small server rack’s worth of GPUs in the trunk.
Nice article! I work in edge AI and I've been writing about this topic for a while. One of the most interesting things to me is how edge compute will break the subscription-based model and result in a rush for cheaper devices:
> The most immediate impact of on-device intelligence is a reduction in recurring costs. Imagine trading cloud infrastructure for a more capable local device. While faster processors are more expensive per unit, they are still far cheaper than the expense of hosting—and staffing—the gigantic infrastructure required to make a cloud application work.
> To sell a system that depends on the cloud, device manufacturers are forced into the subscription business model. All that hosting costs money, which is impossible to recoup from device sales alone. This is why so many modern gadgets come with a significant monthly fee. While subscription revenue can be useful for companies, it reduces the accessibility of products and limits their overall market.
Taken from my article here: https://dansitu.substack.com/p/disconnectivity
Wow. Incredible work here. This is the exact type of thought that is needed right now.
I think there is a pretty large disconnect between the capabilities, and the cost of those capabilities for the average person. Very curious to see how it plays out.